Advent of Code 2020 Day 3
If you thought the purpose of Advent of Code was to really solidify yourself as a big brain programmer, I feel you are sorely mistaken. The real point of Advent of Code is to give you problems of varying difficulty that you can use in order to figure out just what assumptions you make that are wrong. The real point of Advent of Code is to get you some experience with debugging things because you decided to use the "wrong type" or the "wrong function call" or you need "min" rather than "max" because your brain is trying to work too fast. Today, I made the mistake of trying to report a large multiplication as an int and that cause me to go through and debug, at a way too fine-grained level, the logic of a single iteration of my work. After I got my solution working (with nasty for loops) I converted my code to streams and REALLY found out just how much I need to start using the Java 8 Stream library more on a regular basis.
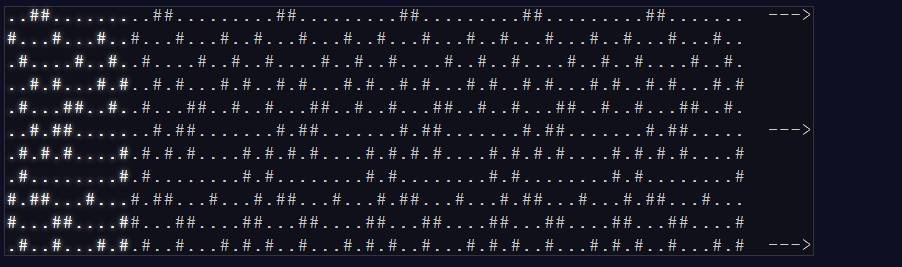
In today's Day 3 puzzle of Advent of Code, we were given an input from a file that contained lines with both . and # characters. We're told the . represent "open spaces" while the # represent trees. Since we fixed the toboggan login problem yesterday we can now attempt to travel by our toboggan through the trees. We're told that we traverse from the top-left to the be below the bottom row. The map pattern that is part of our input repeats to the right for infinite times (we're told this is some sort of arboreal genetic trait of our current biome) which means we know the full pattern until we get to the bottom of the map. The toboggan is only allowed to travel at a single slope, the example (and for part one) slope is down 1, right 3.
Before I got into my explanation, my code for solution is here and here for the tests. Feel free to ignore my crazy rambling below, but I have some interesting insights and have a good comparison of processing code that's a bit more strange from non-stream Java to stream-based Java.
From my experience in previous advents of code (and from the first day puzzle) I know that the slopes (down 1, right 3) are going to be the variable input, so for the part one puzzle, I make the right and down moves a method input so I can use multiple inputs as desired. Note that when you get to part one, you don't know the steps that might need to be taken for part two. I converted my "read" function from days one and two to read into a List of Strings (I tried to stream a 2-d character array, but that failed horribly) which would be streamable, but I couldn't quite figure out how to stream that for the logic (more on that later). I used two out-of-loop variables and a for loop to traverse the map and look for the ultimate goal of this problem, which was the number of trees that I encounter in my toboggan following the given map input at the given slope. With the continuous repeating of the map, you can leverage the modulo operator % in order to continue the pattern without having to actually copy that data over for future use.
List<String> map = getMapFromFile(fileName);
int count = 0;
int rightPos = 0;
for(int downPos = 0 ; downPos < map.size() ; downPos+=downMove) {
if(map.get(downPos).charAt(rightPos%map.get(downPos).length()) == '#') {
count++;
rightPos += rightMove;
}
}
return count;
While this code accomplishes the task, it accomplishes it only in the sense that it's quick and dirty. While an int return works here, it also came back to bite me in the butt for part two (and I'll explain that later), but I'll clue you in that I should probably have returned a long all along so, my stream adaptation of this will return a long instead of an int. The stream adaptation of this is as follows:
List<String> map = getMapFromFile(fileName);
return IntStream.range(0, map.size())
.filter(downPos -> downPos % downMove == 0)
.filter(downPos -> map.get(downPos)
.charAt((downPos*rightMove/downMove)%map.get(downPos).length()) == '#')
.count();
This makes two changes here, the first is that the first filter filters the down positions (from 0 to the number of rows in the map) to only those that are evently incremented from the downMove. While the current example only uses a downMove of 1, part two has an instance where downMove is 2. The second change is that rightPos is now determined by downPos, the rightMove, and the downMove. While the downMove this is all for the same reason as the first change, downMove changes from 1 to 2 in the future. The first filter means we only look at those rows that are properly numbered, [0, 2, 4, 6, ..] when the downMove is 2, or [0, 1, 2, 3, ..] when the downMove is 1. The calculation of the rowPos works since when the downMove is 1 the division is factored out. We know that downPos will only be a value that evenly divides, so we don't have to worry about decimals in this scenario. Both of these provide the same output (only difference being int vs. long) but the calculation is cleared up quite a bit more with the second option and doesn't create unnecessary variables. This solves the first part for me and provides pretty good context into how it worked in my case.
Part two (as expected) wanted to vary the rightMove and downMove but the item I didn't see coming was for a given list of right/down move specifications, to take the product of those values. Using the example, we had already calculated right 3, down 1; but we needed to calculate the tree intersections for right 1, down 1; right 3, down 1; right 5, down 1; right 7, down 1; and right 1, down 2. That last movement directive was the basis of the change in my above code, in case you didn't see the connection before. For this work, I just created a List of integer arrays for each of the moves [[1, 1], [3, 1], [5, 1], [7, 1], [1, 2]] and went through that list and called the tree count method and then multiplied them together. Got my final value and...it was wrong, it was considered to be "low" by the entry input.
It was wrong, not because my individual calculations were wrong, but don't think I didn't go down the path of painstakingly going line-by-line in my code to make sure my individual calculations matched (they did, by the way, but I went down that rabbit hole for a solid 10-15 minutes bashing my head against the wall trying to figure out the problem). After a lot of debugging, I went to open up the windows calculator to do the multiplication by hand, and it didn't match the one my code was presenting. Morgan Freeman Narrator Voice It was at that time, David realized he fucked up /Morgan Freeman Narrator Voice. I converted the return of int to return of long and finally got the correct value and realized, yet again, my move led to problems (it happens frequently, but it's kind of nice to document this, finally).
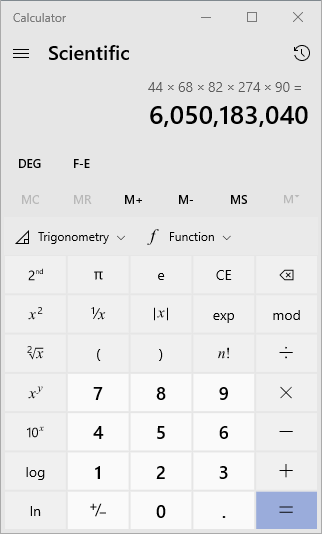
For those who are unaware, integers (at least in Java) are limited to (2^31)-1 and as you can see my result was larger than that (2,147,483,647). I was unfortunate that my product ended up being positive because I thought it was normal, (if it were between 2,147,483,648 and 4,294,967,296 it would've been negative and more easily discernable, but I double-overflowed my value instead, yay luck of the draw, I guess.
I guess, one of my lessons learned is that I definitely need to do a better job myself of using the appropriate data types for calculations, any integer should use a long just to preserve things (I got plenty of RAM), decimals should use double or BigDecimal, just be better about things. Again, if you want to join my Advent of Code leaderboard, feel free to join with the code: 699615-aae0e8af. Looking forward to the next day of Advent of Code myself, and to yet again make a fool of myself.





Member discussion